
Articles from MLCommons

Standardizing AI PC Performance with Expanded Models, Prompts, and Hardware Support
By MLCommons · Via GlobeNewswire · July 30, 2025
More submissions, new hardware accelerators, and more multi-node systems
By MLCommons · Via GlobeNewswire · June 4, 2025
World leader in AI benchmarking announces new partnership with India’s NASSCOM; updated reliability grades for leading LLMs
By MLCommons · Via GlobeNewswire · May 29, 2025

Today, MLCommons® announced new results for its industry-standard MLPerf® Inference v5.0 benchmark suite, which delivers machine learning (ML) system performance benchmarking in an architecture-neutral, representative, and reproducible manner. The results highlight that the AI community is focusing much of its attention and efforts on generative AI scenarios, and that the combination of recent hardware and software advances optimized for generative AI have led to dramatic performance improvements over the past year.
By MLCommons · Via Business Wire · April 2, 2025

MLCommons, in partnership with the AI Verify Foundation, today released v1.1 of AILuminate, incorporating new French language capabilities into its first-of-its-kind AI safety benchmark. The new update – which was announced at the Paris AI Action Summit – marks the next step towards a global standard for AI safety and comes as AI purchasers across the globe seek to evaluate and limit product risk in an emerging regulatory landscape. Like its v1.0 predecessor, the French LLM version 1.1 was developed collaboratively by AI researchers and industry experts, ensuring a trusted, rigorous analysis of chatbot risk that can be immediately incorporated into company decision-making.
By MLCommons · Via Business Wire · February 11, 2025
MLCommons®, the leading open engineering consortium dedicated to advancing machine learning (ML), is excited to announce the public release of the MLPerf® Client v0.5 benchmark. This benchmark sets a new standard for evaluating consumer AI performance, enabling users, press, and the industry to measure how effectively laptops, desktops, and workstations can run cutting-edge large language models (LLMs).
By MLCommons · Via Business Wire · December 11, 2024
MLCommons today released AILuminate, a first-of-its-kind safety test for large language models (LLMs). The v1.0 benchmark – which provides a series of safety grades for the most widely-used LLMs – is the first AI safety benchmark designed collaboratively by AI researchers and industry experts. It builds on MLCommons’ track record of producing trusted AI performance benchmarks, and offers a scientific, independent analysis of LLM risk that can be immediately incorporated into company decision-making.
By MLCommons · Via Business Wire · December 4, 2024
Today, MLCommons® announced new results for the MLPerf® Training v4.1 benchmark suite, including several preview category submissions using the next generation of accelerator hardware. The v4.1 round also saw increased participation in the benchmarks that represent generative AI model training, highlighting the strong alignment between the benchmark suite and the current direction of the AI industry.
By MLCommons · Via Business Wire · November 13, 2024
Today, MLCommons® announced results for its industry-standard MLPerf® Storage v1.0 benchmark suite, which is designed to measure the performance of storage systems for machine learning (ML) workloads in an architecture-neutral, representative, and reproducible manner. The results show that as accelerator technology has advanced and datasets continue to increase in size, ML system providers must ensure that their storage solutions keep up with the compute needs. This is a time of rapid change in ML systems, where progress in one technology area drives new demands in other areas. High-performance AI training now requires storage systems that are both large-scale and high-speed, lest access to stored data becomes the bottleneck in the entire system. With the v1.0 release of MLPerf Storage benchmark results, it is clear that storage system providers are innovating to meet that challenge.
By MLCommons · Via Business Wire · September 25, 2024
Today, MLCommons® announced new results for its industry-standard MLPerf® Inference v4.1 benchmark suite, which delivers machine learning (ML) system performance benchmarking in an architecture-neutral, representative, and reproducible manner. This release includes first-time results for a new benchmark based on a mixture of experts (MoE) model architecture. It also presents new findings on power consumption related to inference execution.
By MLCommons · Via Business Wire · August 28, 2024
MLCommons® and the Autonomous Vehicle Computing Consortium (AVCC) have achieved the first step toward a comprehensive MLPerf® Automotive Benchmark Suite for AI systems in vehicles with the release of the MLPerf Automotive benchmark proof-of-concept (POC). The POC was developed by the Automotive benchmark task force (ABTF), which includes representatives from Arm, Bosch, Cognata, cKnowledge, Marvell, NVIDIA, Qualcomm Technologies, Inc., Red Hat, Sacramento State University, Samsung, Siemens EDA, and UC Davis amongst others.
By MLCommons · Via Business Wire · June 18, 2024
Today, MLCommons® announced new results for the MLPerf® Training v4.0 benchmark suite, including first-time results for two benchmarks: LoRA fine-tuning of LLama 2 70B and GNN.
By MLCommons · Via Business Wire · June 12, 2024
Today in Singapore, MLCommons® and AI Verify signed a memorandum of intent to collaborate on developing a set of common safety testing benchmarks for generative AI models for the betterment of AI safety globally.
By MLCommons · Via Business Wire · May 31, 2024
Today, MLCommons® announced new results from our industry-standard MLPerf® Inference v4.0 benchmark suite, which delivers industry standard machine learning (ML) system performance benchmarking in an architecture-neutral, representative, and reproducible manner.
By MLCommons · Via Business Wire · March 27, 2024
Today MLCommons® is announcing the formation of a new MLPerf™ Client working group. Its goal is to produce machine learning benchmarks for client systems such as desktops, laptops, and workstations based on Microsoft Windows and other operating systems. The MLPerf suite of benchmarks is the gold standard for AI benchmarks in the data center, and we are now bringing our collaborative, community-focused development approach and deep technical understanding of machine learning (ML) towards creating a consumer client systems benchmark suite.
By MLCommons · Via Business Wire · January 24, 2024

Today, MLCommons® announced new results from two industry-standard MLPerf™ benchmark suites:
By MLCommons · Via Business Wire · November 8, 2023
Today, MLCommons®, the leading AI benchmarking organization, is announcing the creation of the AI Safety (AIS) working group. The AIS will develop a platform and pool of tests from many contributors to support AI safety benchmarks for diverse use cases.
By MLCommons · Via Business Wire · October 26, 2023

Today, MLCommons, the leading open AI engineering consortium, announced new results from two MLPerf™ benchmark suites: MLPerf Inference v3.1, which delivers industry standard Machine Learning (ML) system performance benchmarking in an architecture-neutral, representative, and reproducible manner, and MLPerf Storage v0.5. This publication marks the first ever release of results from the MLPerf Storage benchmark, which measures the performance of storage systems in the context of ML training workloads.
By MLCommons · Via Business Wire · September 11, 2023
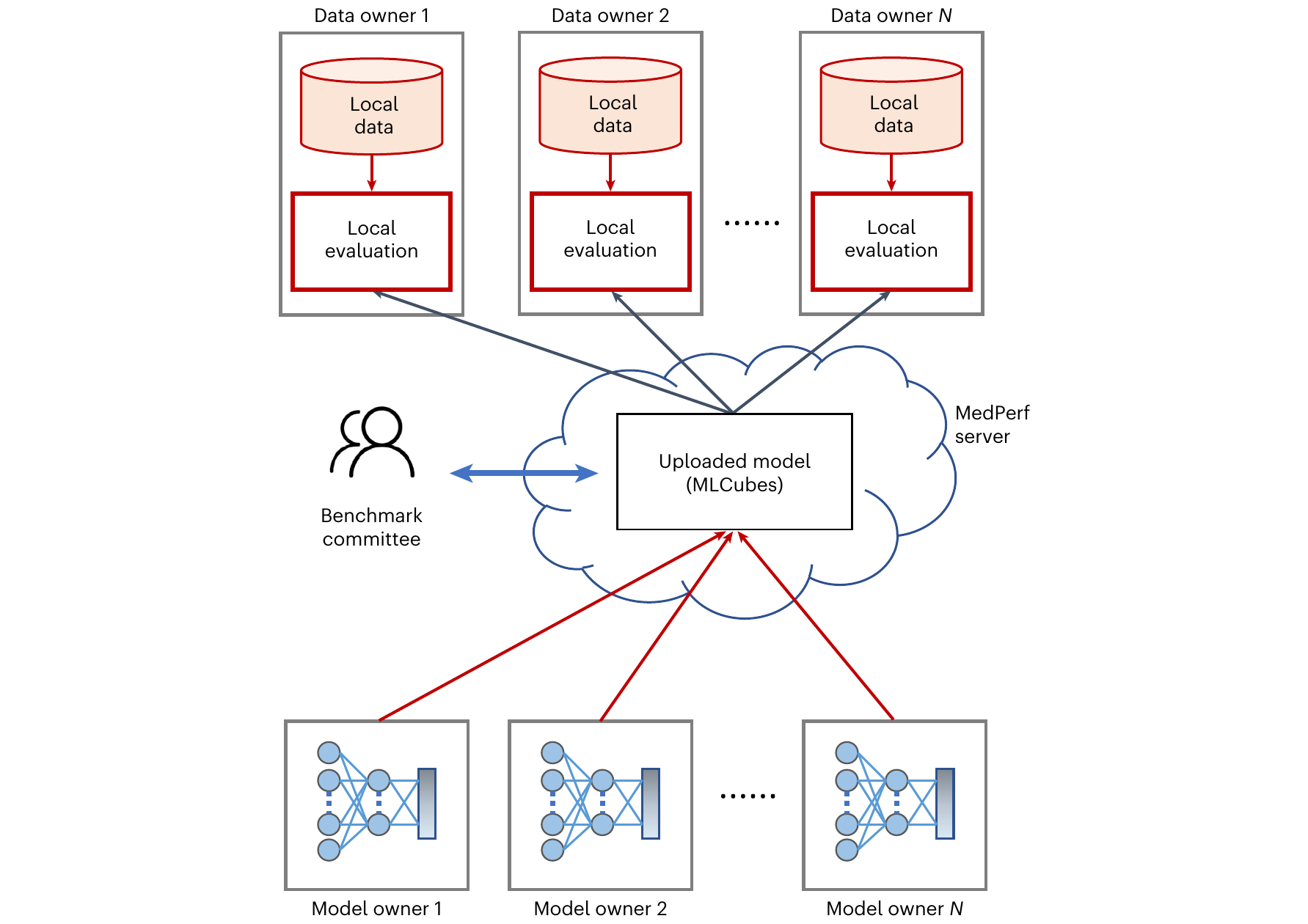
Medical Artificial Intelligence (AI) has tremendous potential to advance healthcare and improve the lives of everyone across the world, but successful clinical translation requires evaluating the performance of AI models on large and diverse real-world datasets. MLCommons®, an open global engineering consortium dedicated to making machine learning better for everyone, today announces a major milestone towards addressing this challenge with the publication of Federated Benchmarking of Medical Artificial Intelligence with MedPerf in the Nature Machine Intelligence journal.
By MLCommons · Via Business Wire · July 17, 2023

Today, MLCommons®, an open engineering consortium, announced new results from two industry-standard MLPerf™ benchmark suites: Training v3.0 which measures the performance of training machine learning models; and Tiny v1.1 which measures how quickly a trained neural network can process new data for extremely low-power devices in the smallest form factors.
By MLCommons · Via Business Wire · June 27, 2023

Today, MLCommons®, the leading open AI engineering consortium, announced new results from the industry-standard MLPerf™ Inference v3.0 and Mobile v3.0 benchmark suites, which measure the performance and power-efficiency of applying a trained machine learning model to new data. The latest benchmark results illustrate the industry’s emphasis on power efficiency, with 50% more power efficiency results, and significant gains in performance by over 60% in some benchmark tests.
By MLCommons · Via Business Wire · April 5, 2023

Today, MLCommons®, an open engineering consortium, announced new results from the industry-standard MLPerf™ Training, HPC and Tiny benchmark suites. Collectively, these benchmark suites scale from ultra-low power devices that draw just a few microwatts for inference all the way up to the most powerful multi-megawatt data center training platforms and supercomputers. The latest MLPerf results demonstrate up to a 5X improvement in performance helping deliver faster insights and deploy more intelligent capabilities in systems at all scales and power levels.
By MLCommons · Via Business Wire · November 9, 2022
Today, the open engineering consortium MLCommons® announced fresh results from MLPerfTM Inference v2.1, which analyzes the performance of inference - the application of a trained machine learning model to new data. Inference allows for the intelligent enhancement of a vast array of applications and systems. This round established new benchmarks with nearly 5,300 performance results and 2,400 power measures, 1.37X and 1.09X more than the previous round, respectively, reflecting the community's vigor.
By MLCommons · Via Business Wire · September 8, 2022
Today MLCommons®, an open engineering consortium, released new results from MLPerf™ Training v2.0, which measures the performance of training machine learning models. Training models faster empowers researchers to unlock new capabilities such as diagnosing tumors, automatic speech recognition or improving movie recommendations. The latest MLPerf Training results demonstrate broad industry participation and up to 1.8X greater performance ultimately paving the way for more capable intelligent systems to benefit society at large.
By MLCommons · Via Business Wire · June 29, 2022
Today MLCommons™, an open engineering consortium, released new results for three MLPerf™ benchmark suites - Inference v2.0, Mobile v2.0, and Tiny v0.7. These three benchmark suites measure the performance of inference - applying a trained machine learning model to new data. Inference enables adding intelligence to a wide range of applications and systems. Collectively, these benchmark suites scale from ultra-low power devices that draw just a few microwatts all the way up to the most powerful datacenter computing platforms. The latest MLPerf results demonstrate wide industry participation, an emphasis on energy efficiency, and up to 3.3X greater performance, ultimately paving the way for more capable intelligent systems to benefit society at large.
By MLCommons · Via Business Wire · April 6, 2022

Today, MLCommons, an open engineering consortium, released new results for MLPerf Training v1.0, the organization's machine learning training performance benchmark suite. MLPerf Training measures the time it takes to train machine learning models to a standard quality target in a variety of tasks including image classification, object detection, NLP, recommendation, and reinforcement learning. In its fourth round, MLCommons added two new benchmarks to evaluate the performance of speech-to-text and 3D medical imaging tasks.
By MLCommons · Via Business Wire · June 30, 2021

Today, MLCommons, an open engineering consortium, launched a new benchmark, MLPerf™ Tiny Inference, to measure how quickly a trained neural network can process new data for extremely low-power devices in the smallest form factors and included an optional power measurement. MLPerf Tiny v0.5 is the organization's first inference benchmark suite that targets machine learning use cases on embedded devices.
By MLCommons · Via Business Wire · June 16, 2021

Today, MLCommons, an open engineering consortium, released results for MLPerf Inference v1.0, the organization's machine learning inference performance benchmark suite. In its third round of submissions, the results measured how quickly a trained neural network can process new data for a wide range of applications on a variety of form factors and for the first-time, a system power measurement methodology.
By MLCommons · Via Business Wire · April 21, 2021